



Godavari — Advancing AI Language Models for Telugu Speakers
The AI landscape has witnessed significant disruption with the introduction of scalable and deployable Large Language Models (LLMs), capable of understanding and generating natural language, as well as music, code, images, and more, with remarkable accuracy. Llama-2 is one such open-source LLM developed by Meta, which has outperformed other open-source LLMs on multiple benchmarks. While it is recognized for its exceptional performance in the English language, its proficiency in other languages, particularly Indic languages, is limited due to restricted exposure. Therefore, we are extending its capabilities to the Telugu language, a language spoken by over 81 million people primarily in the Indian states of Andhra Pradesh and Telangana.
LLMs are Autoregressive models that predict the next element in a sequence, with each element depending on the preceding elements. The paradigm shift in their capabilities has been realized by the introduction of Transformers, a deep learning architecture that has led to advancements in natural language processing (NLP) and language modeling that were previously unimaginable. Built upon the transformer architecture, which relies on the self-attention mechanism, these models have surpassed traditional methods in their ability to analyze and generate text with high levels of coherence and relevance across various tasks.
Llama 2
LLaMA-2 is distinguished by its vast capacity to assimilate diverse content from libraries of human knowledge, enabling not only profound linguistic fluency but also a rich understanding of context-specific information. By continuously pushing computational and algorithmic boundaries, models like LLaMA-2 are revolutionizing language technologies and creating new pathways for AI to integrate seamlessly into daily human activities, enriching communication, enhancing decision-making, and democratizing access to information on a global scale.
While its proficiency in English is commendable, there was a clear need for such models to embrace the linguistic diversity represented by Indic languages. To integrate Indic languages into LLMs, we chose to begin with Telugu and Llama-2. Our initiative has produced a Llama-2 iteration tailored for Telugu—a classical language with a rich literary heritage.

How to Tune LLMs (Llama-2) for a New Language?
LLMs need to be pre-trained on a large dataset in the target language. Pre-training is an unsupervised learning task where the LLM is trained to predict the next “token” given the last N tokens. As long as the data used for pre-training captures the linguistic properties of the language, experiments show that current state-of-the-art (SOTA) LLMs can capture the language distribution. Once the LLM performs decently in the language, it can be fine-tuned to specific tasks in that language. Fine-tuning is a supervised learning task, similar to seq2seq translation. Therefore, pre-training (PT) and fine-tuning (FT) must be performed in order after preparing the data.
Tailoring Tokenizers for Telugu
Tokenization is a critical pre-processing step where text is segmented into tokens (words, subwords, or characters) that the language model can process. Although Llama-2 and its tokenizer have been trained on multilingual data, including Telugu, its tokenization for the Telugu language limits its performance in Telugu-related tasks.
Why Does It Matter?
LLMs (and any transformer) predict the next token based on previous ones, heavily relying on tokenization. Efficient tokenization results in fewer tokens per sentence, allowing the LLMs to utilize their ability to process and generate large sequences more effectively.

Llama tokenizer tokens for “మా తెలుగు తల్లికి మల్లెపూదండ; మా కన్న తల్లికి మంగళ హారతులు.” Too many tokens.
How Did We Tackle It?
We adopted the Alpaca’s approach. Using the SentencePiece framework, we trained a Byte Pair Encoding-based tokenizer on CulturaX (a vast collection of multilingual data, including high-quality Telugu language samples) with a vocabulary size of 16,000. We then merged it with the existing Llama-2 tokenizer vocabulary of 32,000, resulting in a vocabulary of 49,503 tokens comprising both Telugu and English tokens. In similar experiments, we observed improved tokenization for transliterated Telugu text.

Pre-Training on CulturaX
The pre-training phase is crucial as it allows the model to learn the structural and contextual nuances unique to Telugu. We used the CulturaX dataset for this purpose, enabling our model to digest half a billion Telugu tokens over several iterations, internalizing the syntax, semantics, and idiomatic expressions indigenous to the Telugu language, thus setting the stage for fine-tuning.
The Llama-2 was pre-trained for 1 epoch on about 30% data from a mix of Wikipedia Telugu and CulturaX Telugu using an A100 machine for around 14 hours.
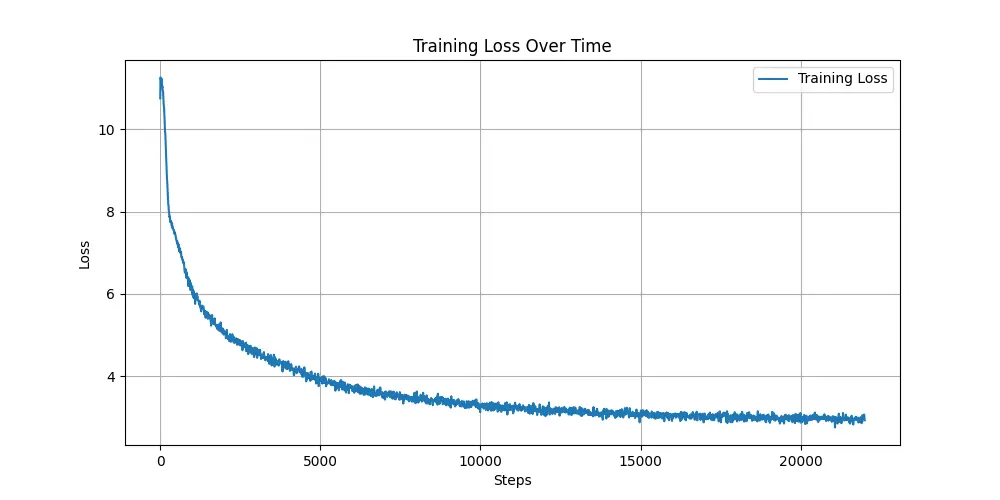
Fine-Tuning with Focused Intent
After the model acquired knowledge related to the Telugu language, it was fine-tuned on an instruction set to refine the model’s understanding of contextually relevant Telugu usage. The data for this task also followed Alpaca’s strategy. We translated the 52k samples instruction set used by the Alpaca team into Telugu.
We fine-tuned the model for 3 epochs for 2 hours on 50% selected data from alpaca using an A100 machine.
A few samples are from this model are shown here.
Prompt
మూడు ప్రాధమిక చిట్కాలు ఇవ్వండి
Response
- ఒక ప్రణాళికను రూపొందించడానికి ముందు, మీరు ఏమి సాధించాలనుకుంటున్నారో ఆలోచించండి; 2. మీ ప్రణాళికను చిన్న, సాధించదగిన లక్ష్యాలుగా విభజించండి; 3. పురోగతిని కొలవడానికి మరియు ట్రాక్ చేయడానికి ఒక వ్యవస్థను ఏర్పాటు చేయండి.
Prompt
మూడు ప్రాధమిక గ్లోబల్ వార్మింగ్ కారణాల ఏమిటి?
Response
- శిలాజ ఇంధనాలను కాల్చడం ద్వారా వాతావరణంలోకి విడుదలయ్యే కార్బన్ డయాక్సైడ్ మరియు మీథేన్ వంటి గ్రీన్హౌస్ వాయువుల అధిక స్థాయిలు; 2. అటవీ నిర్మూలన మరియు వ్యవసాయ పద్ధతుల కారణంగా భూమి యొక్క ప్రతిబింబ ప్రాంతం పెరగడం; 3. పారిశ్రామిక ప్రక్రియలలో నీటి కాలుష్యం పెరుగుదల.
Prompt
విద్యా రంగంలో సాంకేతిక పరిజ్ఞానాన్ని ఎలా ఉపయోగిస్తున్నారనేదానికి అయిదు ఉదాహరణలు ఇవ్వండి.
Response
- విద్యార్థులను నిమగ్నం చేయడానికి మరియు వారి అభ్యాసానికి మద్దతు ఇవ్వడానికి ఇంటరాక్టివ్ వైట్బోర్డులను ఉపయోగించడం; 2. ఆన్లైన్ కోర్సుల నుండి వీడియో ఉపన్యాసాల వరకు విద్యార్థులకు మరింత ఆకర్షణీయమైన అభ్యాస అనుభవాన్ని సృష్టించడానికి మల్టీమీడియా కంటెంట్ను ఉపయోగించడం; 3. విద్యార్థుల ఫలితాలను విశ్లేషించడానికి మరియు వారి అభ్యాస సామర్థ్యాన్ని మెరుగుపరచడానికి విద్యార్థుల పనితీరు డేటాను విశ్లేషించడం; 4. విద్యార్థులను కనెక్ట్ చేయడానికి మరియు ప్రాజెక్టులలో సహకరించడానికి అనుమతించే వర్చువల్ తరగతి గదులు మరియు సహకార సాధనాలను ఉపయోగించడం; 5. విద్యార్థులను లక్ష్యాలను సాధించడంలో ప్రోత్సహించడానికి మరియు ప్రేరేపించడానికి బహుమతులు మరియు గుర్తింపులను అందించడం.
Commitment to Open Science
Reflecting the collaborative spirit essential to AI research, we commit to sharing our contributions with the global community. The fine-tuned Telugu Llama-2 model Godavari is now live at PosteriorAI/godavari-telugu-llama2-7B on huggingface. All the associated datasets and training methodologies will also be made openly accessible, inviting researchers and practitioners to explore and build upon our foundation. This initiative emphasizes our dedication to fostering an inclusive AI ecosystem where technology transcends language barriers, democratizes access, and encourages innovation from every linguistic background.
Future Work: Elevating Indic Language AI
Language Model Release Cadence
On our path to democratizing AI across languages, we are thrilled to announce an ambitious plan: the weekly release of a language-specific LLM. This initiative aims to rapidly expand the linguistic reach of our technology, ensuring that more communities can benefit from these advancements. By systematically addressing a wide array of languages, we are not only empowering non-English speakers with AI but also preserving linguistic diversity in the digital age.
Unified Model and Linguistic Benchmarks
Alongside individual language models, we are developing a unified language model, a polyglot AI capable of understanding multiple languages effortlessly. To evaluate these models, we are also creating comprehensive benchmarks for Indic languages, establishing a gold standard for assessing AI language proficiency and ensuring our models meet the highest performance standards.
Model Optimization and Multimodal Integration
To increase model accessibility, we are focusing on quantization to ensure our AI runs efficiently on various platforms. We are also exploring multimodal capabilities, integrating text, image, and audio processing to unlock new AI applications. A detailed roadmap of these advancements will be shared, outlining the exciting developments ahead.
Commercial Work: AI Solutions for the Marketplace
Commercial Licensing and Exclusive Models
While our open-source releases are not licensed for commercial use, we have developed a suite of commercial solutions. For businesses seeking the competitive edge of AI, we offer exclusive licenses to advanced models specifically designed for commercial applications. These enhanced models provide robust AI capabilities, meeting the demanding needs of the enterprise environment.
Custom LLM Services
Our commercial offerings bridge the gap between cutting-edge AI research and practical business applications. We offer personalized services to develop custom LLMs for institutional clients, ensuring that their specific needs are met with precision-engineered AI solutions. Our affordable LLM inference services democratize access to AI, enabling organizations to incorporate state-of-the-art language modeling into their workflows without significant financial investment.
Conclusion
The Godavari — Telugu Llama project represents a significant advancement in making language models more inclusive. By adapting Llama-2 for the Telugu language, we aim to set a precedent for future initiatives that seek to bring the benefits of AI to the full spectrum of human languages, particularly Indic languages. We believe that technology should reflect the diversity of its users, and with Telugu Llama, we take a deliberate step in that direction. We invite the broader AI community to join us on this journey toward a more linguistically inclusive future, where every language finds its voice in the digital realm.